$ whoami

|
SRE & Observability Engineer
I design monitoring systems, automation pipelines, and internal tools at scale. Over the years I've worked across DevOps and SRE - from building CI/CD pipelines and migrating infrastructure to Kubernetes, to owning the full observability stack across 100+ clusters. When existing tools don't solve the problem, I build custom solutions - from full-scale internal products to alert pipelines to custom exporters.
Sofia, BG / CKA Certified / 10+ Years
Latest internal product I shipped - try the interactive demo
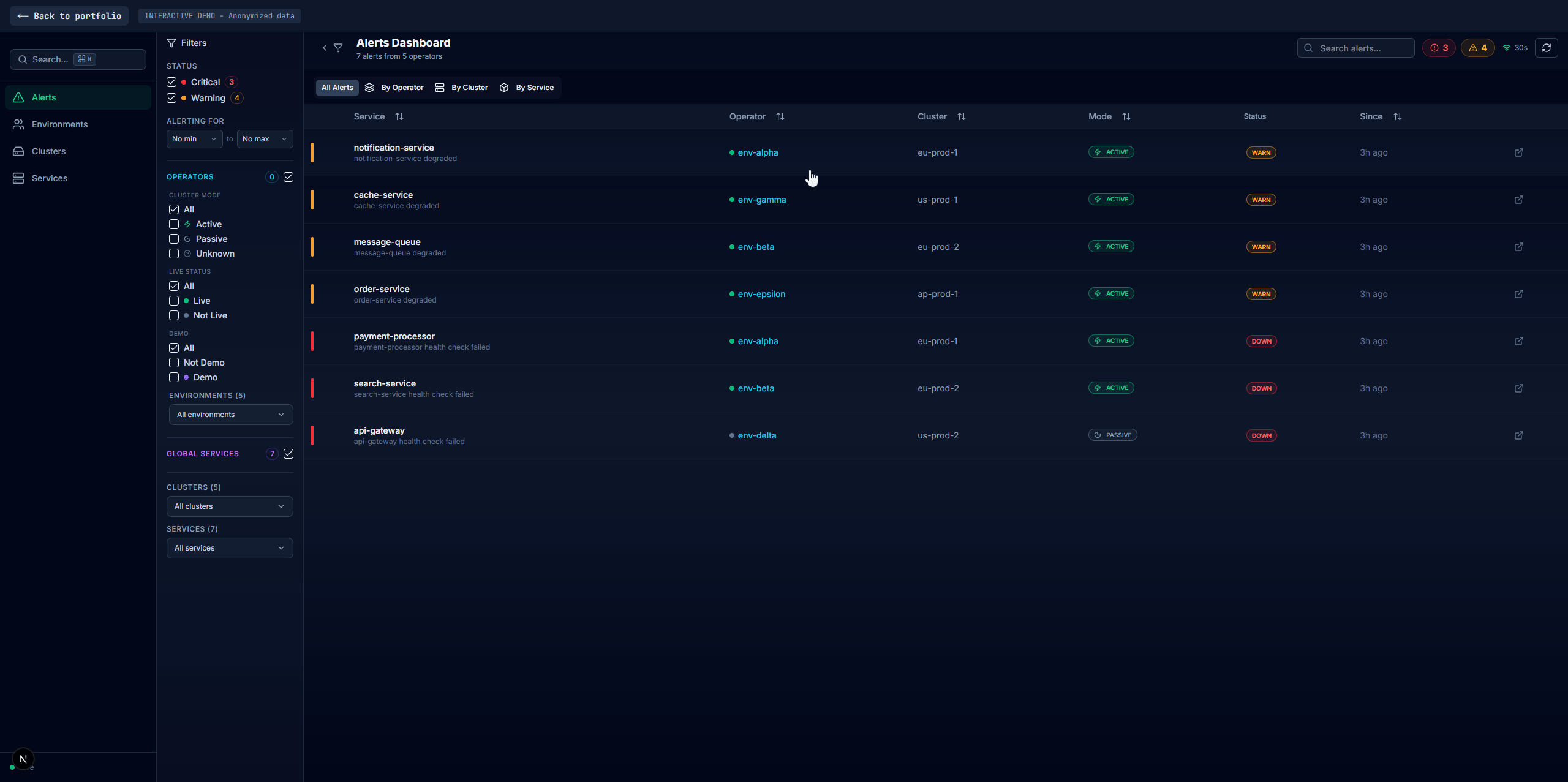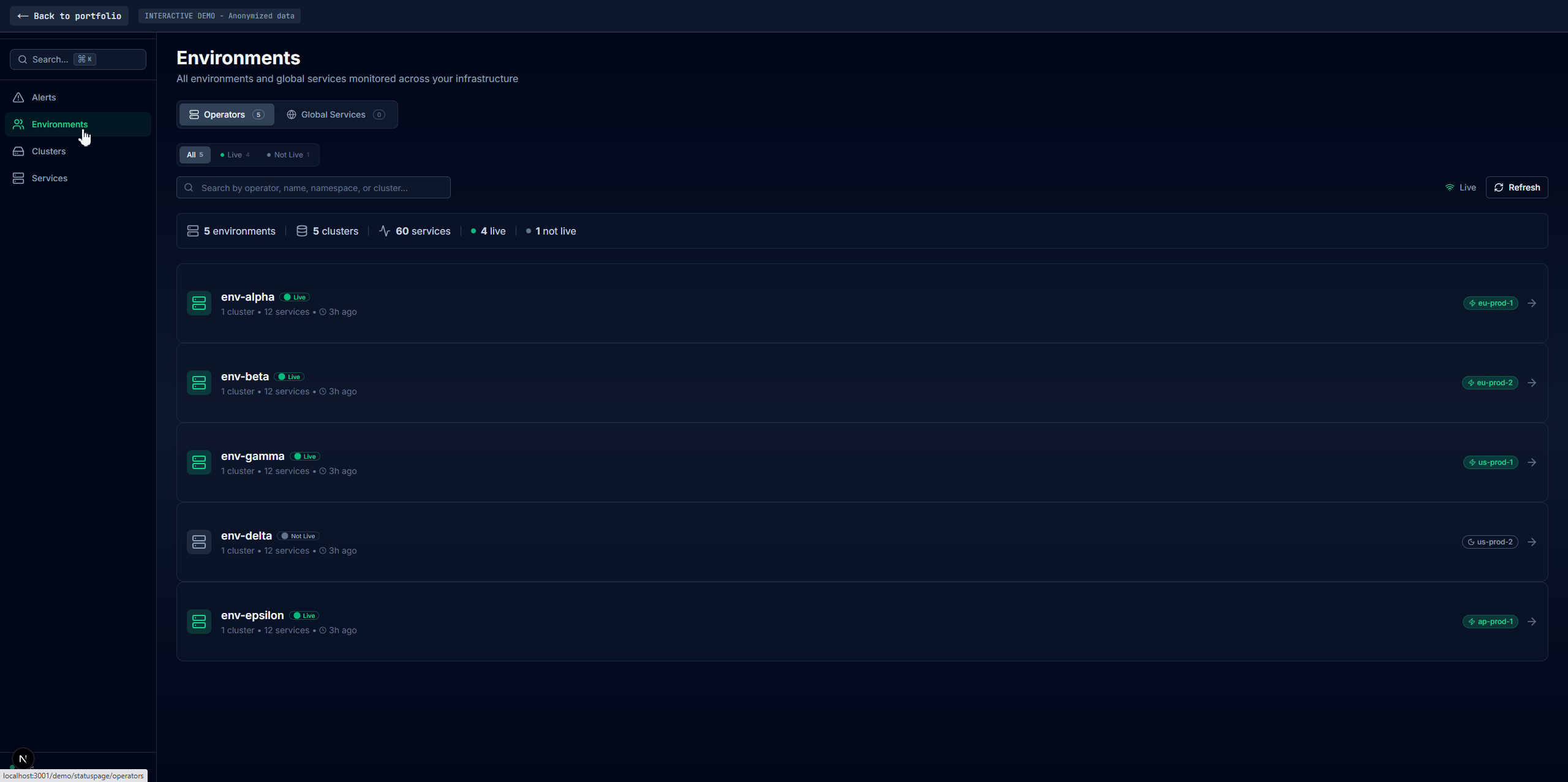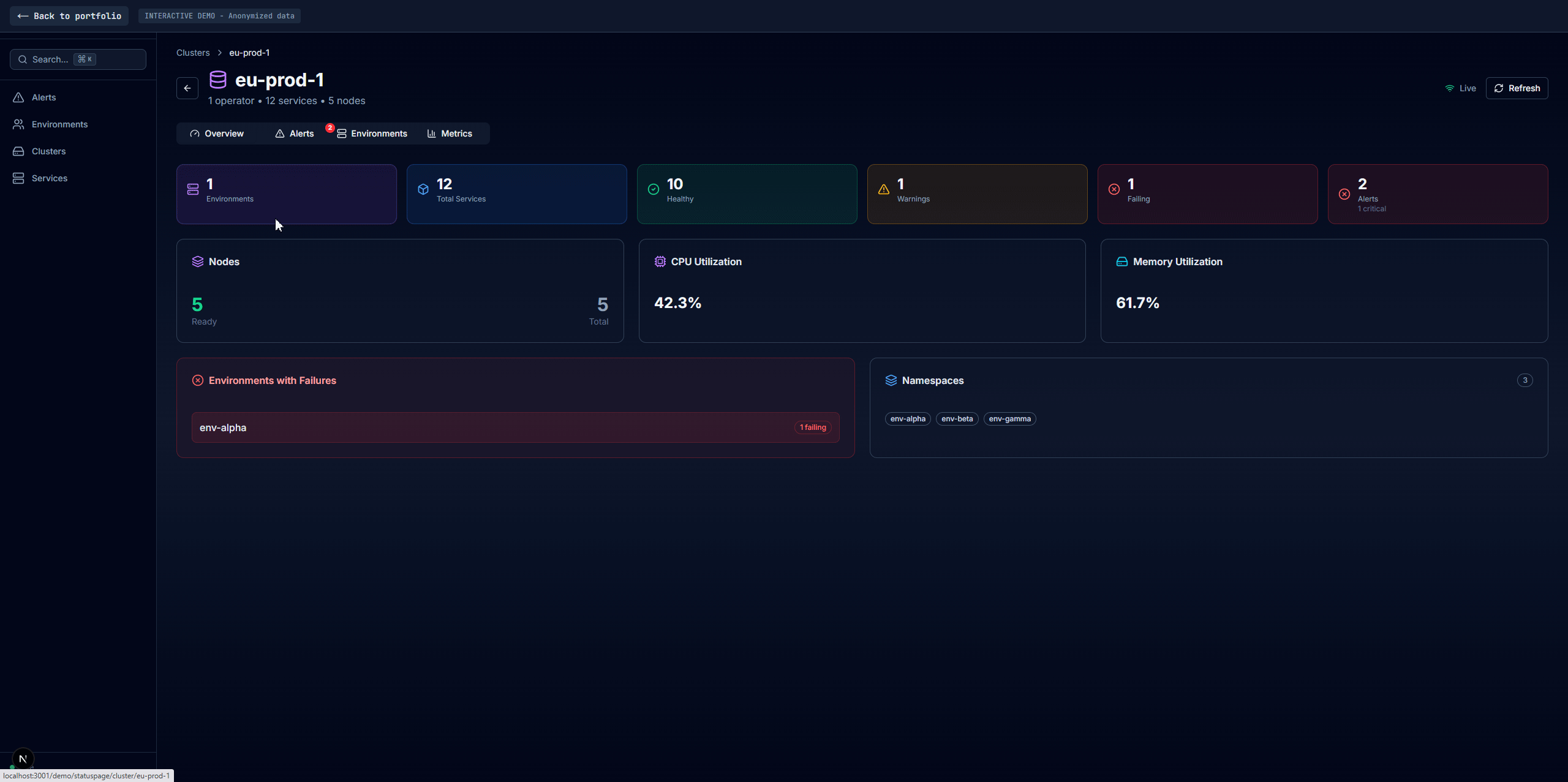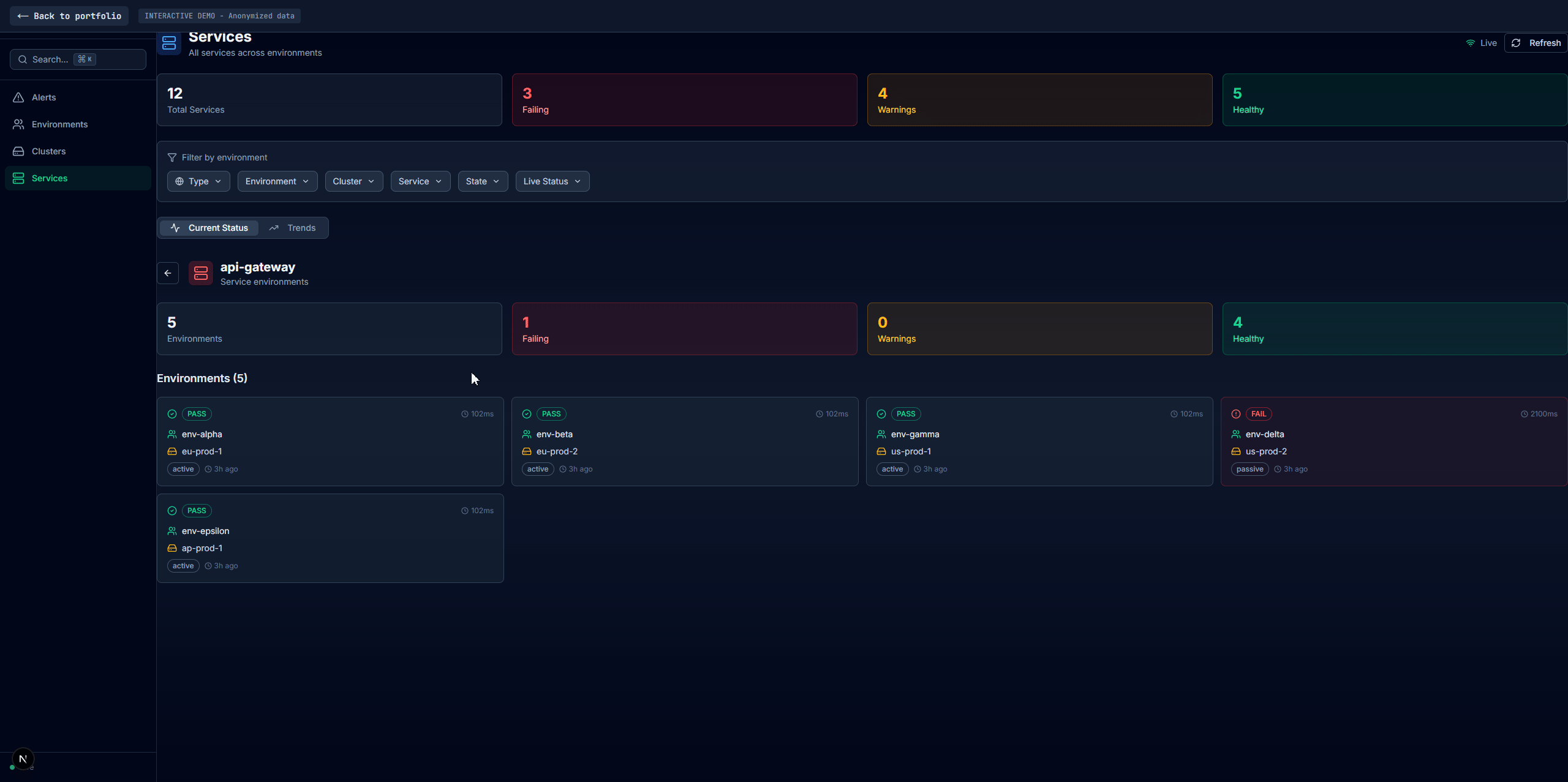
Built a health monitoring platform with auto-discovery, distributed caching, and a multi-view dashboard used daily by operations teams
12M+
Logs/Day
350+
Environments
<50ms
Response Time
30s
Refresh Cycle
Architecture
The Problem
Hundreds of environments across 100+ clusters with no global health view. Each had its own healthchecker page on a different domain. To check health you needed to know which cluster, which namespace, and which URL. PRTG monitored endpoints but every one had to be added by hand. Standard Prometheus tools (Blackbox Exporter, JSON Exporter) don't solve this either because they still require manual target configuration. The company needed a single status page.
Auto-Discovery
Built a per-cluster exporter that discovers healthchecker services via the Kubernetes API automatically. On each cycle it finds all namespaces matching the healthchecker pattern, runs concurrent HTTP checks, and pushes structured results to VictoriaLogs. New environments get picked up on the next discovery cycle with zero configuration. Each health check entry carries up to 170KB of structured JSON: dependency status, response times, operation counts, pod status, resource usage, HPA state.
Why Logs, Not Metrics
The healthchecker data isn't numeric. It's nested JSON with variable-depth dependency trees. Flattening it into Prometheus metrics would lose the dependency relationships and create cardinality problems. VictoriaLogs preserves the full structure and makes it queryable with LogsQL. If starting from scratch I'd design for metrics, but the existing healthchecker constraint made logs the right choice.
The Caching Layer
12M+ logs per day can't be queried on every page load. A Python cache worker runs every 30 seconds with a LogsQL deduplication query that uses server-side partitioning to keep only the latest entry per service (query dropped from 90s to under 30s). Results are organized into 4 Redis tiers: global summary (~1KB), failing services only (~10KB), search indexes as sorted sets (~100KB), and full detail per environment (~1MB). All writes are atomic via MULTI/EXEC.
Distributed Processing
A single worker couldn't keep up at scale. Added horizontal scaling with Redis Streams and Consumer Groups. One worker wins a publisher election via a Lua-scripted lock (SET NX EX 45), fetches from VictoriaLogs, and publishes tasks to a stream. All workers consume tasks, Redis distributes each to exactly one consumer. If a worker crashes, unfinished tasks get reassigned after 60 seconds. A 70% threshold prevents partial upstream data from overwriting the cache.
The Dashboard
Four main tabs: Alerts (current failures with firstSeen/failCount duration tracking, no database needed), Environments (per-environment health with full dependency data), Clusters (infra-level aggregation with inline environment drawers), and Services (cross-environment comparison with cascading filters). A shared service detail panel appears across all tabs with Overview, Pods, Dependencies, embedded Grafana, Logs, and raw JSON. Search via Redis sorted sets returns matches in sub-millisecond time.
Alerting
vmalert evaluates rules against VictoriaLogs directly using LogsQL. Alerts are grouped by namespace, cluster, and active/passive state instead of per-service: 15 failing services become one notification. OpsGenie priority is P1 for active clusters, P2 for passive. A silence manager auto-suppresses ~40% of environments that have no live activity.
Deep Dive - 4-Part Blog Series
What I Build and Operate
Interactive - click any workflow to explore
Observability & SRE
Monitoring Stack
Took over an unstable VictoriaMetrics cluster and turned it into a GitOps-managed monitoring stack serving 50M+ time series across 100+ Kubernetes clusters
50M+
Time Series
5.7M/s
Ingestion
26
Storage Nodes
500+
Alert Rules
Architecture
What I Inherited
An unoptimized VictoriaMetrics cluster with vmstorage nodes restarting multiple times per week. The cause: OOM kills during background merge operations that periodically spike memory usage. When a vmstorage node restarts, other nodes pick up extra load, creating a cascade risk. Helm charts were manually applied and frequently out of sync with actual cluster state.
Stabilizing vmstorage
The fix required two changes together. First, limiting vmstorage background operations to 60% of available memory, leaving 40% headroom for queries and ingestion. At 80% the read path was starved and vmselect queries started timing out. Second, moving vmstorage to a dedicated nodepool with pod anti-affinity so merge spikes don't compete with other workloads for memory. After both changes: zero OOM restarts for months.
Fixing vmagent
The team's approach to handling scrape load was adding more vmagent replicas. The problem: each replica scraped all targets, so more replicas meant the same metrics being sent to VictoriaMetrics multiple times. I converted vmagent to a StatefulSet with target sharding (6 shards, each scraping 1/6th of targets). Added persistent storage so if VictoriaMetrics has brief unavailability, vmagent buffers to disk instead of dropping data.
Ingestion and Cardinality
Added a 60-label limit per metric to catch misconfigured exporters that would create millions of unique series. Set vminsert max request size to 64MB. Query timeouts at 30s for vmselect, 10s for labels API. Enabled kube-state-metrics autosharding with gzip encoding, which wasn't enabled before and the raw payload was unnecessarily large. Top cardinality offenders: response codes at 1.6M series and apiserver SLI buckets at 1.5M.
GitOps via Rancher Fleet
Consolidated the entire stack into a single Git repository managed by Rancher Fleet. VictoriaMetrics, Grafana, AlertManager, vmalert, custom exporters, all with per-cluster configs and label-based targeting. Changes go through PR review, Fleet deploys automatically. No SSH, no manual Helm upgrades.
The Numbers
26 vmstorage nodes with 28Gi RAM and 350Gi disk each. vminsert scales from 20 to 100 replicas via HPA. vmselect scales from 20 to 80. Total data: ~3.9TB across 14.4 trillion rows with 30-day retention. Ingestion rate: 5.7 million samples per second.
Disaster Recovery
The entire stack is recoverable from Git. A Terraform-based DR plan provisions a new monitoring cluster, connects to Fleet, and redeploys everything automatically.
Alert Pipeline
Designed a custom severity model that turned alert storms into single, prioritized notifications with automatic silence management
500+
Alert Rules
3
Severity Levels
Fleet
Deployed via
Architecture
The Problem
One incident triggered 10+ pages. A database slowdown would fire critical for complete failure, warning for degradation, and low for elevated latency, all at the same time for the same root cause. No correlation between severities. Passive standby clusters paged with the same urgency as active production. Engineers wrote each severity as a separate rule, so changing a query meant updating three places. With 500+ rules, things drifted.
Template System
I designed a template format where one YAML definition contains all severity levels. Each severity can have completely different expressions, not just different thresholds. A critical might check for complete failure while a warning checks degradation using a different query entirely. A Python generator expands these into standard vmalert rules with automatic severity and severity_order labels. Open-sourced both the generator and a migration tool that converts existing rules into template format.
The CI Pipeline
Fleet doesn't have pre-sync hooks like ArgoCD, so templates can't be transformed at deploy time. I built a Jenkins pipeline: on feature branches, it generates rules locally and validates with vmalert dry-run. No broken expressions reach the main branch. On merge, it generates final rules, commits them to a rules-bundle directory, and pushes with retry logic and rebase. Fleet detects the commit and deploys to vmalert across all clusters.
Inhibition and Routing
The generated rules share the same alertname across severities. AlertManager inhibition suppresses lower severities when a higher one fires: critical suppresses warning/low, warning suppresses low. The on-call engineer sees one alert at the highest applicable severity instead of three. OpsGenie priority is automatic: P1 for critical on active clusters, P2 for passive, P3 for warnings.
Health Check Grouping
For the health monitoring system, alerts are grouped by namespace, cluster, and active/passive state instead of per-service. If 15 services fail in one environment, the on-call gets one grouped notification listing all 15. A 30-second group wait collects related alerts before the first notification. A 2-minute regroup interval catches late arrivals.
Silence Automation
Built a Python service that periodically checks an external business API for environment state. If an environment has no live activity, the silence manager creates a silence in AlertManager for that namespace. When it goes live again, the silence is removed. Handles about 40% of environments at any time. Replaced a manual process where people would create silences and forget to clean them up weeks later.
GitOps & Delivery
Kubernetes Migration
PASTMigrated web applications from bare-metal VMs to Kubernetes on AWS with full CI/CD and GitOps delivery
Architecture
The Problem
Web applications running on bare-metal VMs with manual deployments. No containerization, no CI/CD, no infrastructure as code. Deployments were risky, inconsistent, and required direct server access.
What I Built
Containerized the applications with Docker. Built Helm charts for Kubernetes deployment. Set up CI/CD with GitHub Actions for build and test, ArgoCD for GitOps delivery to EKS. RDS for managed databases, External Secrets for Vault integration. The full path from code push to production with zero manual steps.
The Result
Consistent environments, automated rollbacks, no more SSH-based deployments. The team went from dreading releases to shipping multiple times a day.
Platform Engineering
Custom Services
Built 5+ Python services to fill gaps where off-the-shelf tools didn't exist: exporters, automation, and data collection
Architecture
Why Custom
The monitoring stack had gaps that no existing tool covered. Business state awareness, DNS zone health, dynamic metric generation from label values, automated health discovery across hundreds of namespaces. Each gap needed its own service.
Exporters
- Health Check Exporter - auto-discovers services via Kubernetes API, runs concurrent checks, pushes structured results to VictoriaLogs. The data source for the entire Status Dashboard platform
- DNS Health Exporter - reads Cloud DNS zones and exposes health check status per zone as Prometheus metrics
- Dynamic Metrics Exporter - generates new metrics from label values of existing metrics via YAML config with hot-reload. Example: extracting Kubernetes node version labels into version tracking metrics
- Environment Status Exporter - scrapes a reporting API to expose which environments are live, active, or in demo mode. Feeds into alerting priority and dashboard filtering
Automation
- Silence Manager - checks environment business state, auto-creates AlertManager silences for non-live environments. Handles ~40% of environments at any time
Pattern
All services follow the same pattern: containerized with Docker, deployed via Rancher Fleet, output consumed by VictoriaMetrics or VictoriaLogs. Each solves one specific problem that couldn't be solved with configuration alone.
Atlas
IN DEVInfrastructure topology and incident correlation platform - mapping dependencies from OTel traces, Kubernetes state, and alerting into a graph database
The Problem
Infrastructure dependencies are scattered across multiple systems. When something breaks, engineers manually piece together which services depend on what, check multiple dashboards, and dig through past incidents. There's no single place that shows the full picture.
The Approach
Building a platform that automatically maps infrastructure dependencies from real data - OpenTelemetry traces show service-to-service calls, Kubernetes API shows cluster topology, AlertManager shows what's firing. All stored in Neo4j as a graph so you can trace impact paths deterministically, not through ML guesswork.
What's Built
Topology builder that polls OTel traces and maps dependency edges into Neo4j. Kubernetes agent that watches cluster state via informers. REST API serving the topology to a Next.js frontend. The foundation for incident correlation is in place.
Where It's Going
Deterministic incident resolution - when an alert fires, trace the dependency graph to identify the root cause from actual infrastructure topology. Connect to historical incidents and runbooks for context. The goal is what tools like Dynatrace do with ML, but built on real dependency data.
Latest Posts
View all posts →Auto-Discovery for Dynamic Environments
Why blackbox exporter doesn't scale for dynamic environments, and how I built auto-discovery health monitoring using the Kubernetes API and structured logs.
Caching 12M+ Logs in Real-Time
LogsQL deduplication, a 4-tier Redis cache, and distributed workers with Redis Streams to serve sub-50ms responses from 12M+ daily health check logs.
Designing Views for Hundreds of Environments
How I structured a health monitoring dashboard with four drill-down levels, cascading filters, cross-environment service views, and embedded Grafana panels.
From Logs to Grouped Alerts
Replacing per-service alert noise with grouped notifications by environment, automatic priority based on cluster state, and silence automation for non-live environments.