Status Dashboard
LIVE DEMOBuilt a health monitoring platform with auto-discovery, distributed caching, and a multi-view dashboard used daily by operations teams
12M+
Logs/Day
350+
Environments
<50ms
Response Time
30s
Refresh Cycle
Architecture
The Problem
Hundreds of environments across 100+ clusters with no global health view. Each had its own healthchecker page on a different domain. To check health you needed to know which cluster, which namespace, and which URL. PRTG monitored endpoints but every one had to be added by hand. Standard Prometheus tools (Blackbox Exporter, JSON Exporter) don't solve this either because they still require manual target configuration. The company needed a single status page.
Auto-Discovery
Built a per-cluster exporter that discovers healthchecker services via the Kubernetes API automatically. On each cycle it finds all namespaces matching the healthchecker pattern, runs concurrent HTTP checks, and pushes structured results to VictoriaLogs. New environments get picked up on the next discovery cycle with zero configuration. Each health check entry carries up to 170KB of structured JSON: dependency status, response times, operation counts, pod status, resource usage, HPA state.
Why Logs, Not Metrics
The healthchecker data isn't numeric. It's nested JSON with variable-depth dependency trees. Flattening it into Prometheus metrics would lose the dependency relationships and create cardinality problems. VictoriaLogs preserves the full structure and makes it queryable with LogsQL. If starting from scratch I'd design for metrics, but the existing healthchecker constraint made logs the right choice.
The Caching Layer
12M+ logs per day can't be queried on every page load. A Python cache worker runs every 30 seconds with a LogsQL deduplication query that uses server-side partitioning to keep only the latest entry per service (query dropped from 90s to under 30s). Results are organized into 4 Redis tiers: global summary (~1KB), failing services only (~10KB), search indexes as sorted sets (~100KB), and full detail per environment (~1MB). All writes are atomic via MULTI/EXEC.
Distributed Processing
A single worker couldn't keep up at scale. Added horizontal scaling with Redis Streams and Consumer Groups. One worker wins a publisher election via a Lua-scripted lock (SET NX EX 45), fetches from VictoriaLogs, and publishes tasks to a stream. All workers consume tasks, Redis distributes each to exactly one consumer. If a worker crashes, unfinished tasks get reassigned after 60 seconds. A 70% threshold prevents partial upstream data from overwriting the cache.
The Dashboard
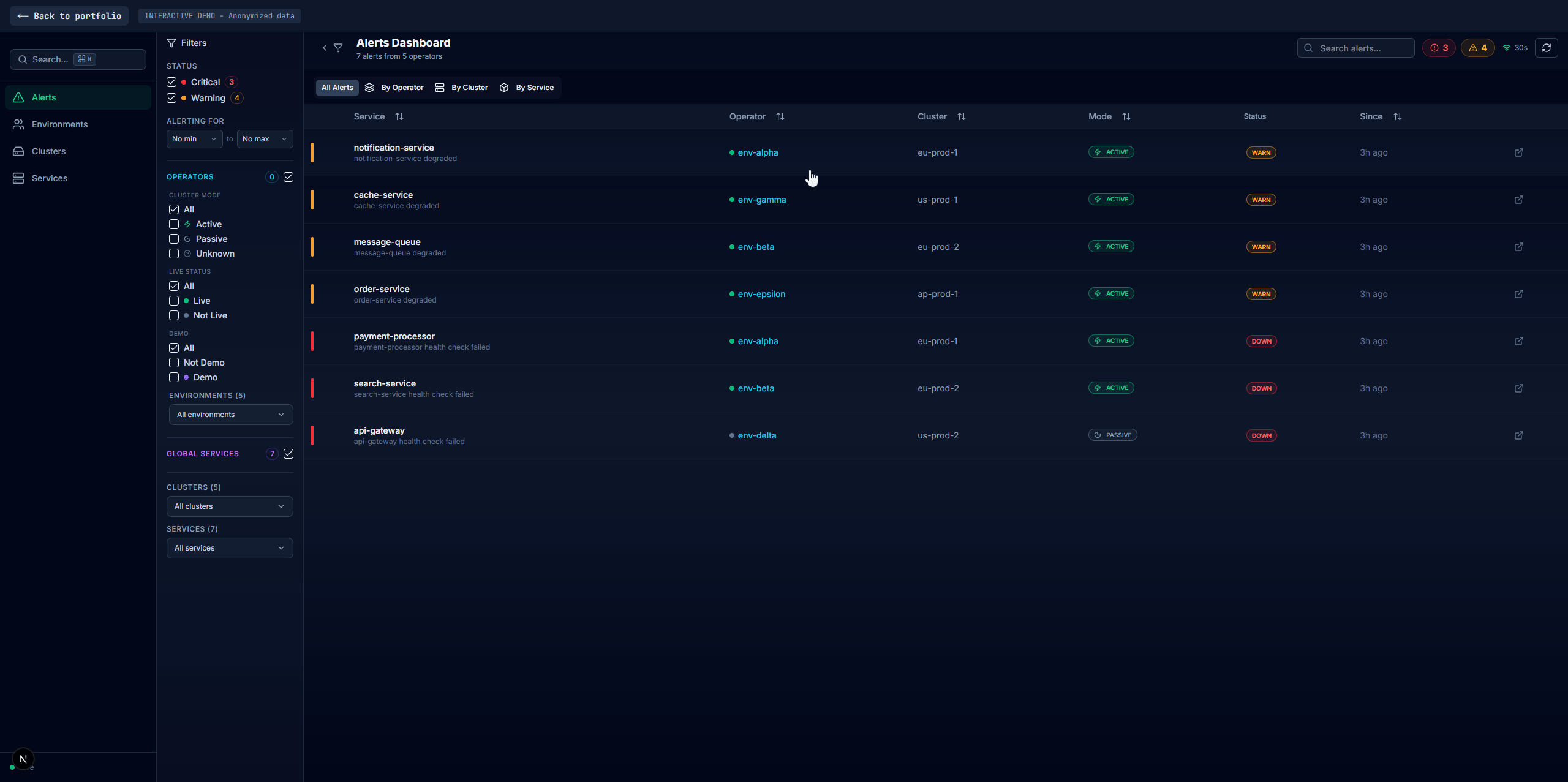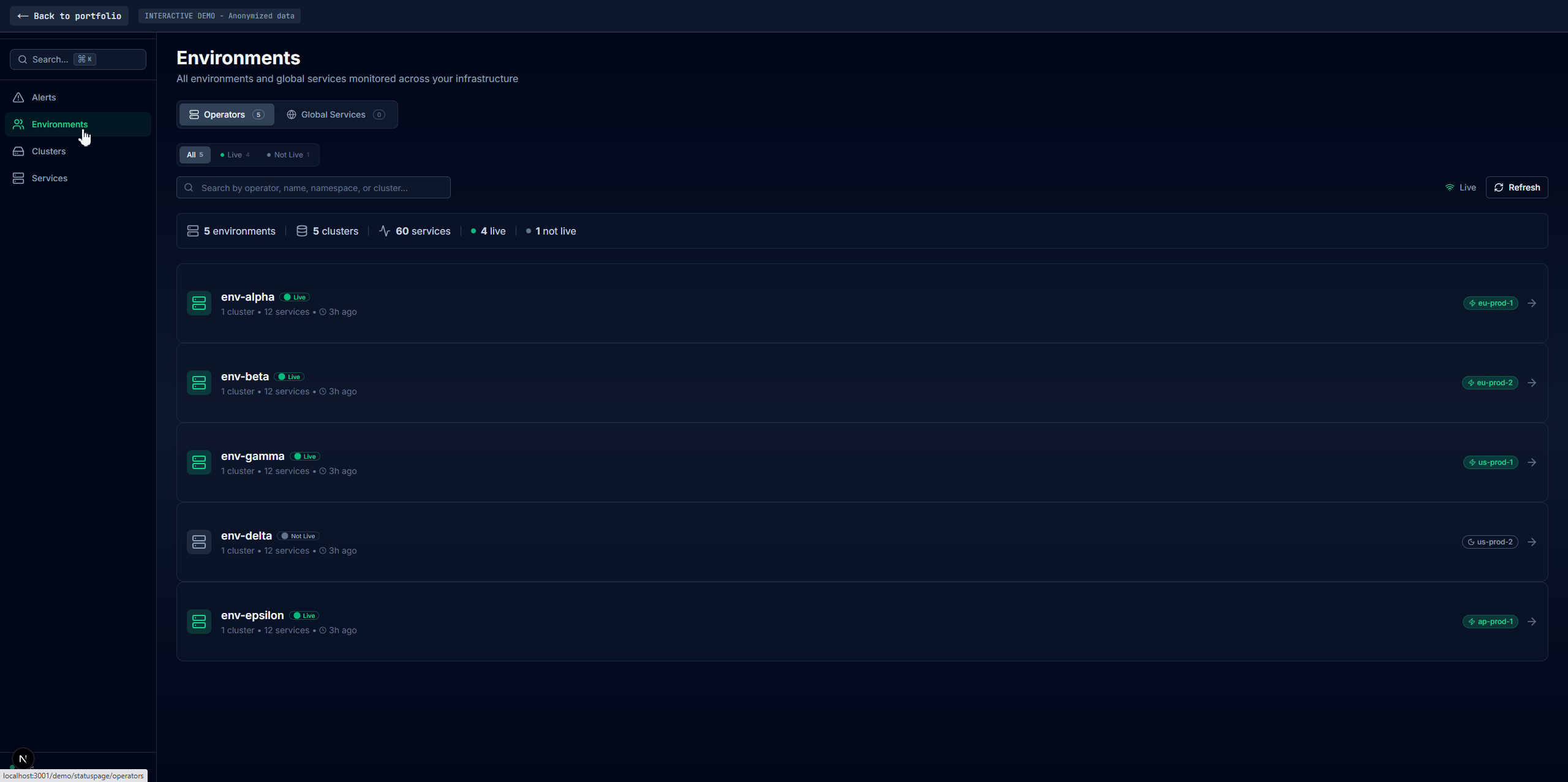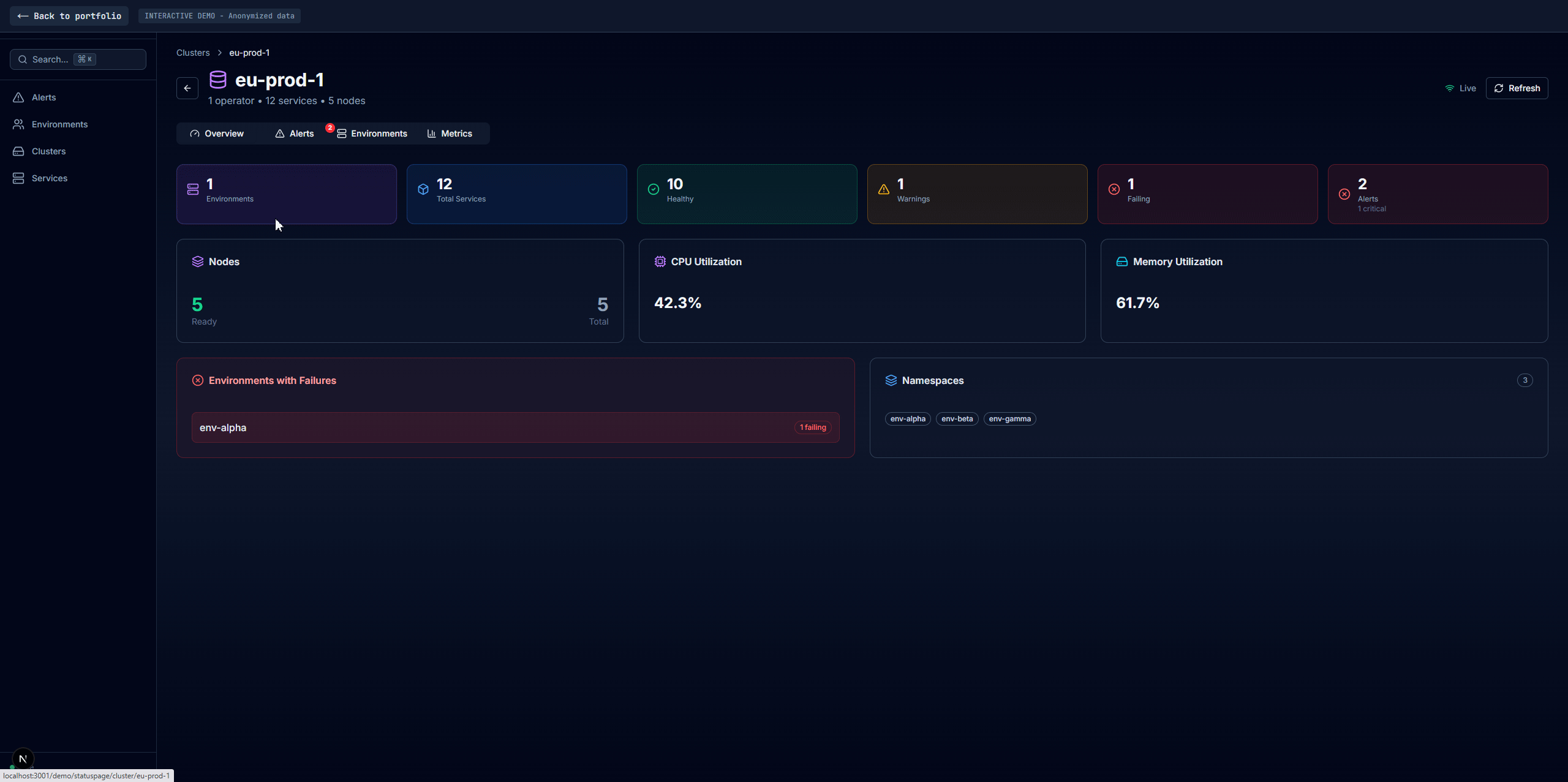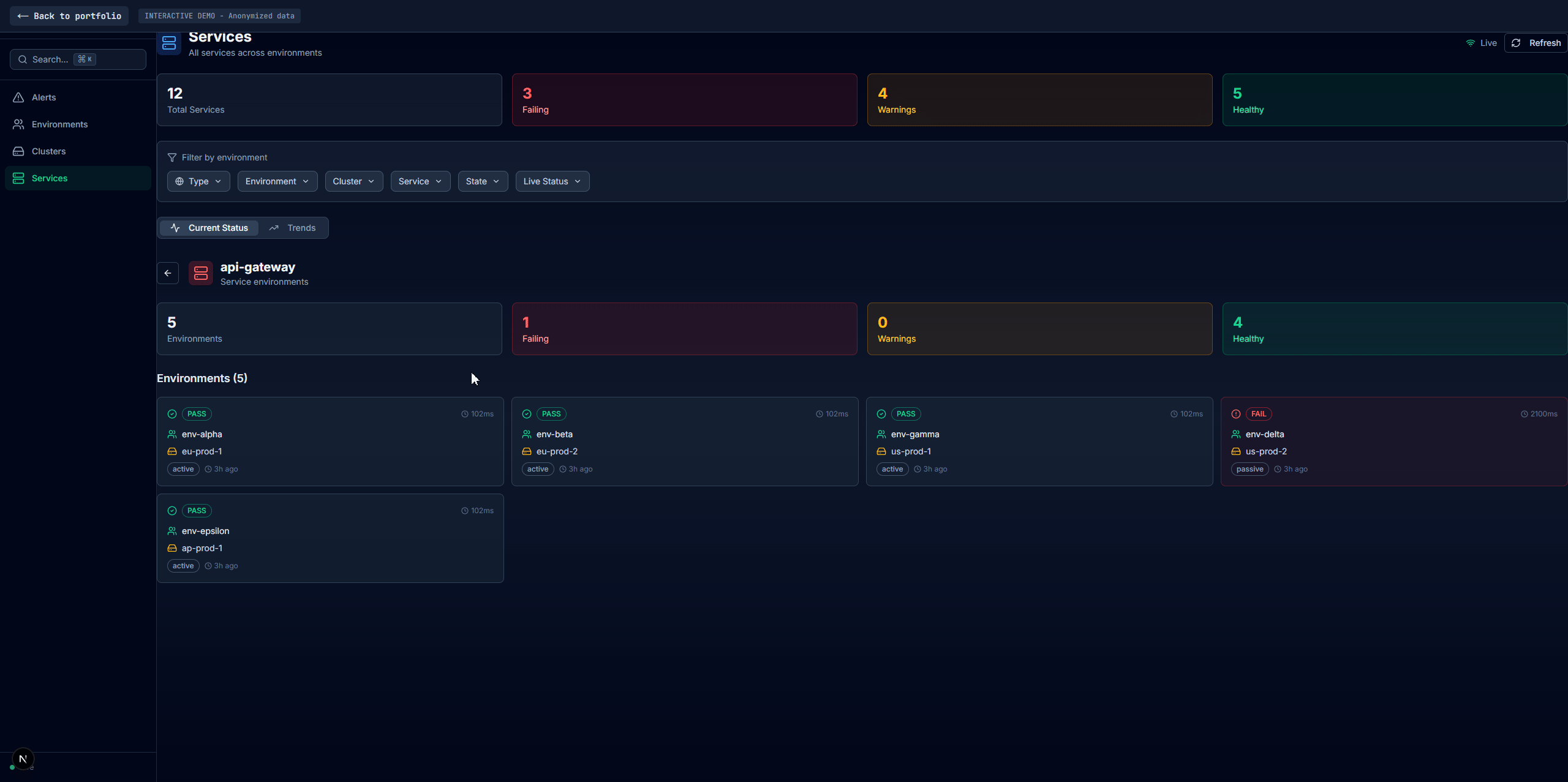
Four main tabs: Alerts (current failures with firstSeen/failCount duration tracking, no database needed), Environments (per-environment health with full dependency data), Clusters (infra-level aggregation with inline environment drawers), and Services (cross-environment comparison with cascading filters). A shared service detail panel appears across all tabs with Overview, Pods, Dependencies, embedded Grafana, Logs, and raw JSON. Search via Redis sorted sets returns matches in sub-millisecond time.
Alerting
vmalert evaluates rules against VictoriaLogs directly using LogsQL. Alerts are grouped by namespace, cluster, and active/passive state instead of per-service: 15 failing services become one notification. OpsGenie priority is P1 for active clusters, P2 for passive. A silence manager auto-suppresses ~40% of environments that have no live activity.
Deep dive